 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-attention Recurrent Network for Human Communication Comprehension
Feb 03, 2018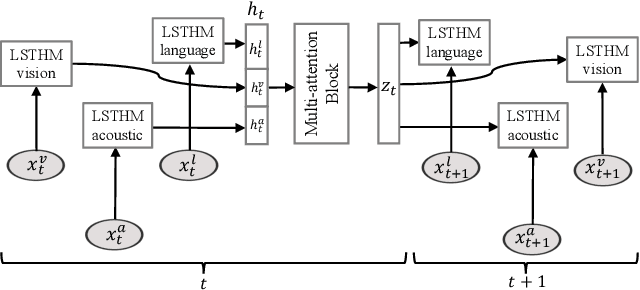
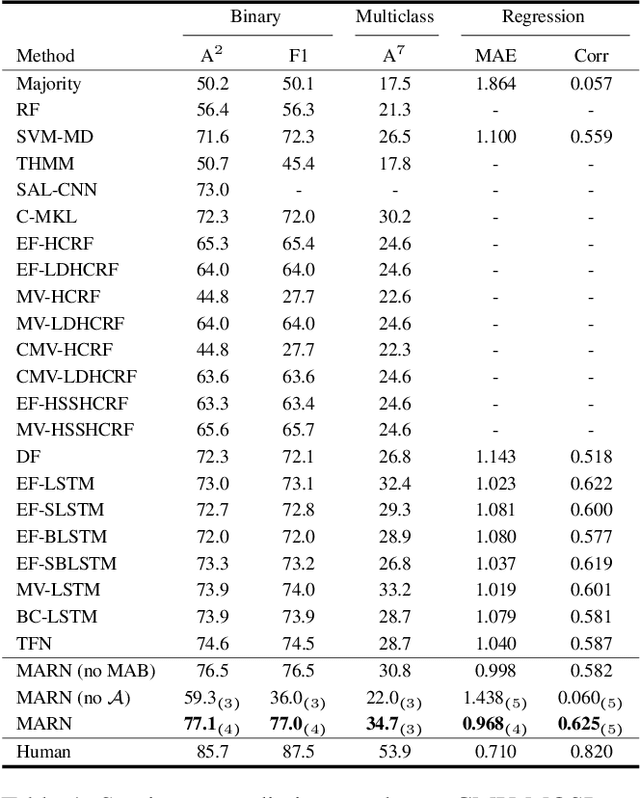
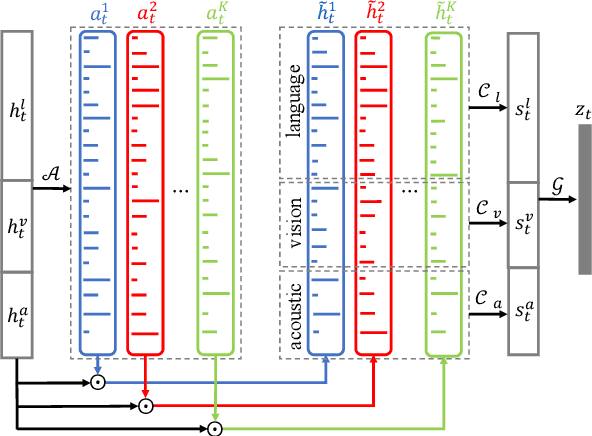
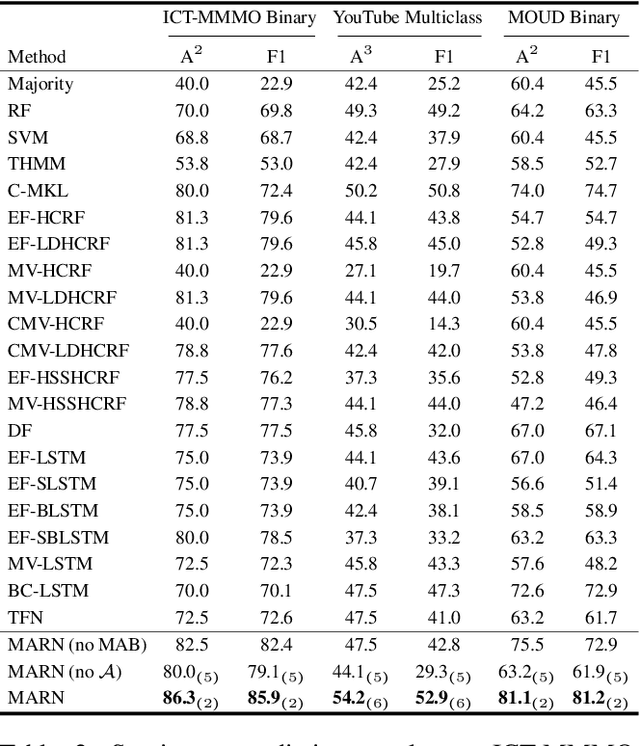
Human face-to-face communication is a complex multimodal signal. We use words (language modality), gestures (vision modality) and changes in tone (acoustic modality) to convey our intentions. Humans easily process and understand face-to-face communication, however, comprehending this form of communication remains a significant challenge for Artificial Intelligence (AI). AI must understand each modality and the interactions between them that shape human communication. In this paper, we present a novel neural architecture for understanding human communication called the Multi-attention Recurrent Network (MARN). The main strength of our model comes from discovering interactions between modalities through time using a neural component called the Multi-attention Block (MAB) and storing them in the hybrid memory of a recurrent component called the Long-short Term Hybrid Memory (LSTHM). We perform extensive comparisons on six publicly available datasets for multimodal sentiment analysis, speaker trait recognition and emotion recognition. MARN shows state-of-the-art performance on all the datasets.
A Deeper Look into Sarcastic Tweets Using Deep Convolutional Neural Networks
Jul 27, 2017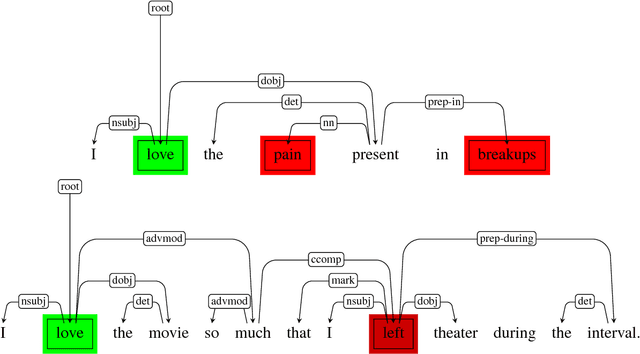

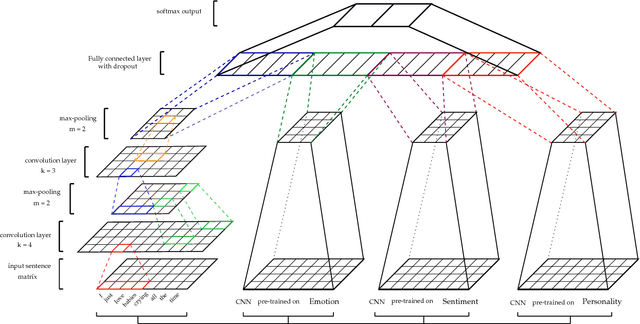
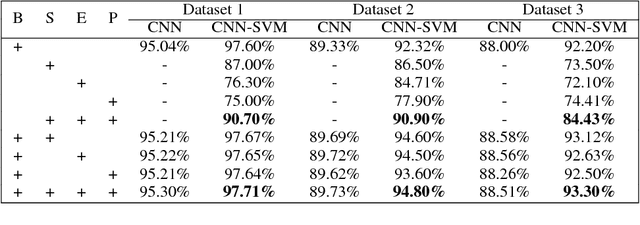
Sarcasm detection is a key task for many natural language processing tasks. In sentiment analysis, for example, sarcasm can flip the polarity of an "apparently positive" sentence and, hence, negatively affect polarity detection performance. To date, most approaches to sarcasm detection have treated the task primarily as a text categorization problem. Sarcasm, however, can be expressed in very subtle ways and requires a deeper understanding of natural language that standard text categorization techniques cannot grasp. In this work, we develop models based on a pre-trained convolutional neural network for extracting sentiment, emotion and personality features for sarcasm detection. Such features, along with the network's baseline features, allow the proposed models to outperform the state of the art on benchmark datasets. We also address the often ignored generalizability issue of classifying data that have not been seen by the models at learning phase.